# 验证码计算 def cal(sen): number = sen.split(':')[1].split('等于')[0] ans = 0 if '加' in sen: ans = int(number.split('加')[0]) + int(number.split('加')[1]) elif '减' in sen: ans = int(number.split('减')[0]) - int(number.split('减')[1]) elif '乘以' in sen: ans = int(number.split('乘以')[0]) * int(number.split('乘以')[1]) elif '除以' in sen: ans = int(number.split('除以')[0]) / int(number.split('除以')[1]) return int(ans)
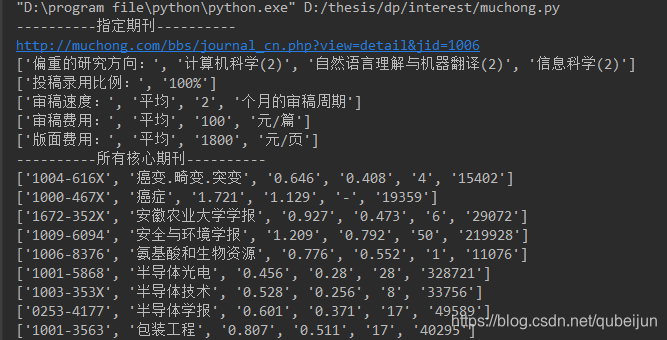
# 期刊 # 第一页 url = 'http://muchong.com/bbs/journal_cn.php' rep2 = conn.get(url, headers=headers) qikan = html.fromstring(rep2.text) head_name = qikan.xpath('//div[@class="wrapper"][8]/div[@class="forum_head"]//td/text()') all_qikan = qikan.xpath('//div[@class="wrapper"][8]/div[@class="forum_body forum_body_journal"]//tbody') for a in all_qikan[:]: x = a.xpath('string(.)') print(x.split())
# 第一页往后 for i in range(2, 23): url = 'http://muchong.com/bbs/journal_cn.php?from=emuch&view=&classid=0&class_credit=0&page=' + str(i) rep2 = conn.get(url, headers=headers) qikan = html.fromstring(rep2.text) head_name = qikan.xpath('//div[@class="wrapper"][6]/div[@class="forum_head"]//td/text()') all_qikan = qikan.xpath('//div[@class="wrapper"][6]/div[@class="forum_body forum_body_journal"]//tbody') for a in all_qikan[:]: x = a.xpath('string(.)') print(x.split())
def journal_name(name): url = 'http://muchong.com/bbs/journal_cn.php' name = name.encode("GBK") postdata = { 'issn': '', 'tagname': '', 'name': name, 'ssubmit': '(unable to decode value)', 'accept-charset': "utf-8" } rep = conn.post(url, data=postdata, headers=headers) qikan = html.fromstring(rep.text) every_qikan = qikan.xpath('//div[@class="wrapper"][6]/div[@class="forum_body forum_body_journal"]//tbody') for a in every_qikan[:]: x = a.xpath('tr/th/a/@href') url = 'http://muchong.com/bbs/'+x[0] print(url) detail(url)
def detail(url): rep = conn.get(url, headers=headers) _detail = html.fromstring(rep.text) # 虫友提供资料 deta = _detail.xpath('//div[@class="wrapper"][4]/div[@class="forum_explan bg_global"][2]//tr') for i in deta: i1 = i.xpath('string(.)') print(i1.split())

 微信
微信 支付宝
支付宝