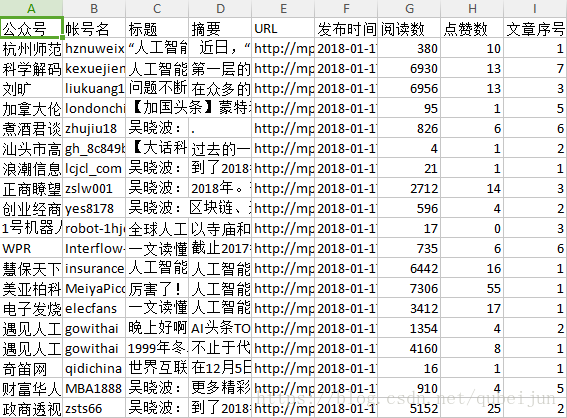
# 微信文章属性:wechat_name wechat_id title abstract url time read like number for v in range(1, n_rows-1): # 每一行数据形成一个列表 values = table.row_values(v) # 列表形成字典 data.append({'wechat_name': values[0], 'wechat_id': values[1], 'title': values[2], 'abstract': values[3], 'url': values[4], 'time': values[5], 'read': values[6], 'like': values[7], 'number': values[8], }) # 返回所有数据 return data
if __name__ == '__main__': d = [] # 循环打开每个excel for i in range(1, 16): d1 = read_xlsx('./excel data/'+str(i)+'.xlsx') d.extend(d1)
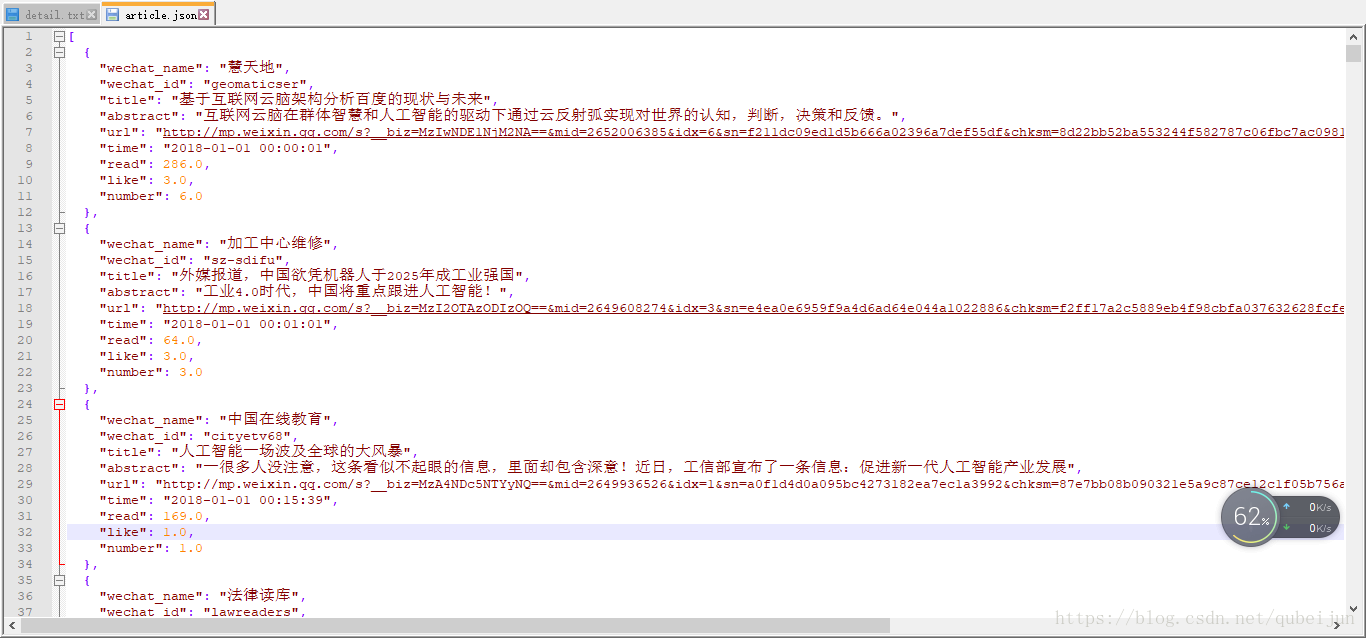
# 微信文章属性 # 按时间升序排列 d = sorted(d, key=operator.itemgetter('time')) # 写入json文件 with open('article.json', 'w', encoding='utf-8') as f: f.write(json.dumps(d, ensure_ascii=False, indent=2))
name = [] # 微信id写文件 f1 = open('wechat_id.txt', 'w') for i in d: if i['wechat_id'] not in name: name.append(i['wechat_id']) f1.writelines(i['wechat_id']) f1.writelines('\n')

 微信
微信 支付宝
支付宝